
Como criar uma base de dados com Python
Base de dados confiáveis, acessíveis e que tenha aderência as necessidades de quem trabalha com análise de dados é um desafio, tanto para quem está iniciando, quanto para quem tem muito tempo de experiência. Nesse post mostro como gerar uma base de dados, que servirá para diversos projetos, a partir de uma base pré-existente.

Photo by christina-wocintechchat.com on Unsplash.
Bases de dados de imagens específicas
A Ciência de Dados sempre parece glamurosa e quem trabalha nela é elevado um nível superior. Nas grandes empresas existem vários cientistas de dados, cada qual trabalhando em uma parte do projeto. Bonito, né! Entretanto, a coisa não é bem assim, na grande maioria dos projetos, desde o boom da Data Science, muitas empresas de diversos portes e filosofias querem e tentam prospectar e minerar o novo minério precioso, os dados. O que muitos não entendem é que para minerar é necessário que exista o minério. Entre a descoberta do minério e ele ser transformado em algo de valor, existe um longo caminho. Deixando as questões filosóficas e entrando direto no assunto, o que quero dizer é que sem uma base de dados não se faz muito. Voltando para a filosofia, onde estão os dados, como vão se coletados, quem vai coletar, quem vai organizar, quem vai tratar, quem vai analisar, pois é, muitas questões.
Quem é que nunca passou pela seguinte situação: ô fulano, tenho uma tabela aqui, vê o tu podes fazer…hehehehe. Aí, a tabela tem 5 medições…hehehe. Ou 5000, mas completamente desorganizada, sem critérios, cheia de dados faltantes e os que tem são os famosos imbalanced data…hehehe.
Cruel, né. Mas foi exatamente a partir dessa adversidade que surgiram os Engenheiros e Cientistas de Dados. Para quem não sabe a diferença entre ambos, vou fazer uma comparação com a Fórmula 1: o engenheiro seria Adrian Newey e o cientista seria Lewis Hamilton. Aí tu vais perguntar, mas é esse Adrian? Primeiro, ele é um dos maiores projetista da F1, de todos os tempos e segundo, os carros que ele projetou já ganharam (até o dia de publicação desse post) dez títulos na F1, ou seja, mais que qualquer piloto, tá bom pra ti. Então, sem desvalorizar ninguém, bem pelo contrário, o que vale é a equipe. Quando alguém falar que o Schumacher foi o cara ou que Hamilton é o cara, não esqueça da equipe (projetista, carro, mecânicos, patrocinadores etc.). Como nem tudo acontece como na F1, em muitos casos o normal é sermos ao mesmo tempo projetista, mecânico e piloto…hehehe. Em outras palavras, muitas vezes, nem os dados temos para trabalhar e temos de produzir nossa própria base de dados, do zero ou derivando-a de outra base.
Outro detalhe importante, mesmo quando utilizamos casos reais, armazenados em bases de dados on-line, por menor que as bases sejam, ainda assim, podem ser extremamente caras. Quando se precisa de bases de dados de imagens específicas, por exemplo, imagens médicas, drones, satélites etc aí a coisa complica e são quase impossíveis de consegui-las.
Ora, estamos num tempo onde a própria internet é uma excelente fonte dos mais diversos tipos de dados abertos, então vamos aproveitá-los ao máximo, seja para treinar ou para uso em projetos. Tem-se inúmeros locais de onde pode-se fazer download de dados voltados a regressão, classificação e para aplicação dos mais variados algoritmos. Mas é necessário fazer um bom garimpo e, se estamos trabalhando com um projeto bem específico, nem sempre encontramos os dados ideais para treinar. É, exatamente, o que aconteceu comigo e acontece com frequência, por isso gerei minha própria base de dados, criada a partir de dados abertos. Aí está outro ponto importante, ter capacidade de gerar seu próprio material de trabalho e por menor que a base seja, tirar o máximo dela é um skill essencial de um competente data scientist…uhuuuu.
Projeto
Então, mãos à obra. O que eu fiz foi, a partir de uma base de dados pré-existente, gerar uma outra que atendesse minhas necessidades. Utilizei a base de [Massas de Água](http://dados.gov.br/organization/39868dc2-d6b8-4b89-84e4-692c2fe17b25?tags=massas) localizadas no Rio Grande do Sul. Na verdade são duas bases, uma refere-se as massas de água do centro para leste (Atlântico Sul) e outra do centro para oeste (Uruguai). No post sobre o Geopandas mostrei como plotar as massas de água com base no seu arquivo shapefile contido na base de dados abertos. Contudo, como os tamanhos das massas de água são muito desproporcionais, muitas ficam praticamente invisíveis no mapa do RS. Por isso tive a ideia de capturá-las, uma a uma e compará-las com o intuito de fazer uma classificação. Nesse post mostrarei como gerar essa base e no próximo, mostrarei como fazer a classificação.
Roteiro
Vamos precisar fazer download dos arquivos necessários, que são as massas de água do Rio Grande do Sul, como já falei: um arquivo é Athantico_Sul.shp e o outro Uruguai.shp.
Antecipadamente, falo que as massas de água são divididas em Artificial e Natural, então, como a ideia e fazer um dataset para uso futuro, ou seja, talvez tu ainda não tenhas em mente o que vais fazer com a base, sugiro deixa-las separadas. O mesmo para as massas de água. Assim, é como se tivéssemos 4 bases ou grupos e, conforme, a necessidade juntamos tudo, mas sempre tendo um controle antecipado para evitar esforço desnecessário depois. Recomento criar uma pasta para cada grupo de outputs.
Tudo é muito simples, desde que se tenha as bibliotecas certas, ahhh não comentei, vamos fazer tudo com Python. Os outros downloads são os pacotes, os principais são geopandas e pyshp, e tu podes usar o pypi para baixá-las.
Importamos os pacotes necessários
import shapefile
import geopandas as gpd
import pandas as pd
import os
from geopandas import GeoDataFrame
import time
from tqdm import tqdm
Em seguida, vamos carregar os arquivos que contém os shapefiles com as massas de água.
# carregando os shapefiles
filepath = '/MASSAS_DAGUA/Atlantico_Sul.shp'
filepath1 = '/MASSAS_DAGUA/Uruguai.shp'
sf = shapefile.Reader(filepath)
sf1 = shapefile.Reader(filepath1)
shapes = sf.shapes()
shapes1 = sf1.shapes()
# transformando em geodataframes
as_gdf= gpd.read_file(filepath)
u_gdf= gpd.read_file(filepath1)
Como pode-se ver no fragmento de código, optei por usar duas vezes os arquivos, uma para fazer operações diretamente nos arquivos geometry do shapefile e o outro para transformar todos os arquivos contidos no shapefile em geodataframe.
Ok, vamos verificar se tudo está correto.
[in]: len(sf), len(sf1)
[out]: (1069, 2024)
Ok, agora, com um único looping vamos percorrer toda a base de dados, ler uma massa de água por vez, identificar se ela é $artificial$ ou $natural$ e conforme a categoria gravá-la em uma pasta separada.
start = time.process_time()
n = len(sf1)
for x in tqdm(range(n)):
bbox_lake1 = shapes1[x].bbox
if records_sf1[x][4] == 'Natural':
xmax, ymax, xmin, ymin = bbox_lake1
ax = df2.plot(column='shape_Area', cmap='viridis', figsize=(14, 8), linewidth=0.5)
ax = df2.plot(ax= ax, linewidth=1.5, color='white', edgecolor='black')
ax.set_xlim([xmax, xmin])
ax.set_ylim([ymax, ymin])
ax.set_facecolor('white')
plt.axis('off')
filename = 'spfuruguai_{:d}.jpg'.format(x)
plt.savefig('FIG_Un/' +filename)
plt.close()
if records_sf1[x][4] == 'Artificial':
xmax, ymax, xmin, ymin = bbox_lake1
ax = df2.plot(column='shape_Area', cmap='viridis', figsize=(14, 8),linewidth=0.5)
ax = df2.plot(ax= ax, linewidth=1.5, color='white', edgecolor='black')
ax.set_xlim([xmax, xmin])
ax.set_ylim([ymax, ymin])
ax.set_facecolor('white')
plt.axis('off')
filename = 'spfuruguai_{:d}.jpg'.format(x)
plt.savefig('FIG_Ua/' +filename)
plt.close()
pass
print((time.process_time() - start)/60)
Comentários: vou comentar somente os fragmentos que são mais importantes no código.
bbox_lake1 = shapes1[x].bbox delimita um bounding box para cada shapefile.
records_sf1[x][4] == 'Natural' confere se a massa de água é Natural
xmax, ymax, xmin, ymin = bbox_lake1 extrai os limites do retângulo
Obs.: toda fração de código destinada a plotagem do polígono é necessária para que o plot seja feito, porém ele é suprimido (plt.axis('off')) de aparecer na tela, mas é gravado na pasta de destino plt.savefig('FIG_Un/' +filename)
Não esqueça de criar uma pasta para cada grupo de output.
Essa fração de código, atuará somente sobre um grupo de massas de água, para repetir sobre a outra é necessário trocar ` n = len(sf1)` pela correspondente e também trocar as pastas onde serão salvas as figuras.
Resultado
Como resultado, obtem-se as imagens dos contornos das respectivas massas de água. Aqui apresento apenas 3 para que possa observar como ficou.
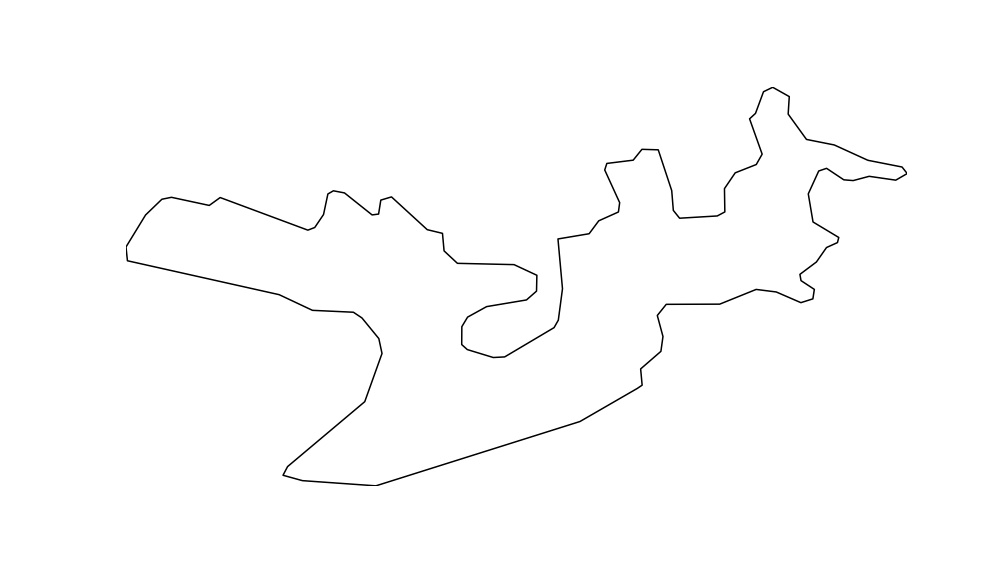
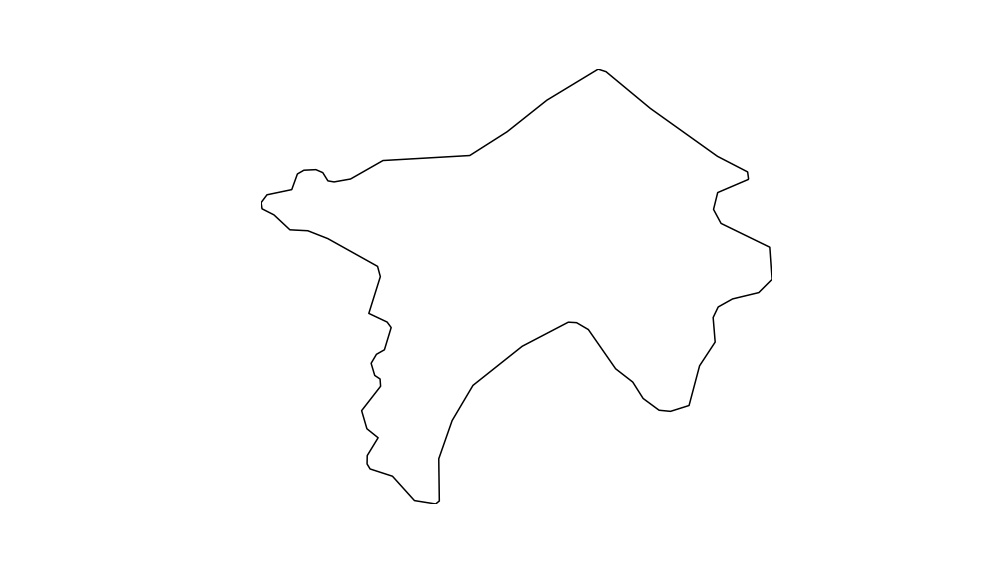
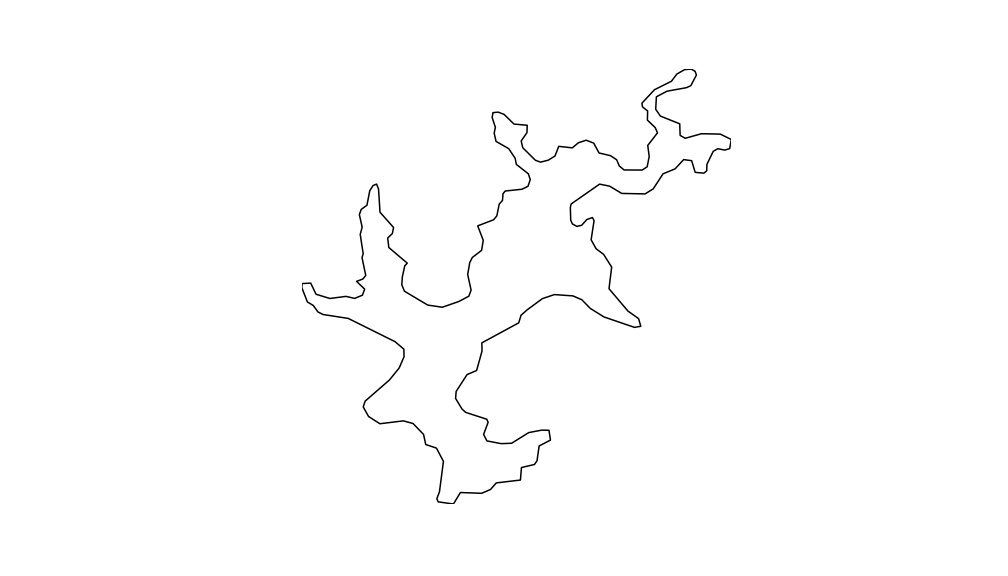
Sugestões de trabalhos futuros
De acordo com a base de dados das imagens que foram capturadas os trabalhos futuros podem ser os mais variados. Algumas sugestões seriam a comparação entre os contornos para verificar se existem semelhanças; comparar as massas de água artificiais com as naturais e ainda, distinção entre os tipos de massas ou contornos.
É isso, em breve mostrarei como construir um modelo classificador de imagens como essa base de dados usando keras.